Mettre en place un fichier robots.txt permet d’indiquer aux robots d’indexation (crawlers) les fichiers ou répertoires à ne pas indexer.
Voici le schéma du fonctionnement de ce fichier :
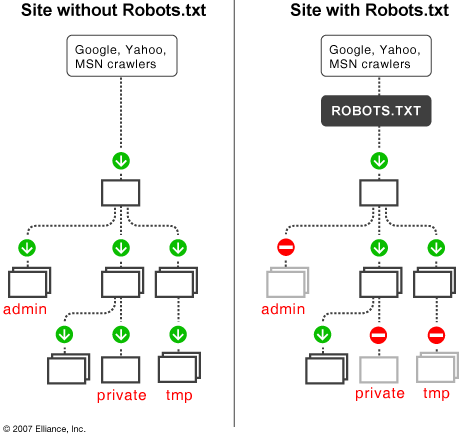
L’intérêt d’un tel fichier est de ne pas faire indexer tel fichier ou tel répertoire, comme par exemple le dossier /wp-admin/ de WordPress… en gros, interdire l’indexation de fichiers non-publics ou qui ne présente aucun intérêt selon vous. Ne vous inquiétez pas, les répertoires exclus resteront accessibles mais ils n’apparaitront pas dans les résultats des moteurs de recherche.
Mettre en place un fichier robots.txt
Ce fichier doit être obligatoirement placé à la racine de votre espace web et contiendra toutes les directives à suivre par les différents robots d’indexation.
Il peut contenir différentes commandes, placées les unes à la suites des autres. Voici un extrait du robots.txt utilisé sur Blog Tool Box :
Sitemap: http://blogtoolbox.fr/sitemap.xml
User-agent: *
Disallow: /phpmv2/
Disallow: /wp-admin/
Disallow: /category/
Disallow: /tag/
La commande Sitemap, placé en tête de liste, permet de localiser le fichier sitemap de votre blog (une carte/plan de votre blog qui permet aux moteurs de recherche de lister l’ensemble des documents au lieu de les crawler et leur permet ainsi de parcourir votre blog plus facilement).
User-agent correspond aux directives à suivre pour tel ou tel robot, l’étoile * permet de prendre en compte tous les robots. Vous pouvez faire différentes règles pour différents robots (voir The Web Robots Database pour obtenir la liste de tous les robots existants).
Exemple de robots.txt comprenant différentes règles pour différents robots :
User-agent: *Dans ce cas, le répertoire /dossier/ est bloqué pour tous les robots sauf pour Googlebot qui lui seul peut indexer le site en entier.
Disallow: /dossier/
User-agent: Googlebot
Disallow:
Toutes les lignes commençants par Disallow permettent d’indiquer les pages ou répertoires à exclure de l’indexation. Chaque chemin doit commencer par un slash / et pour cette commande, l’étoile * ne peut pas être utilisée.
Contrairement à la commande Disallow, la commande Allow, acceptée par certains robots, permet l’autorisation d’indexation. Commande à utiliser dans le cas où vous voulez indexer un fichier à l’intérieur d’un répertoire en Disallow.
Pour finir, vous pouvez tester et valider votre robots.txt grâce aux Outils pour Webmasters de Google.
Voir également le site robots-txt.com pour plus d’informations en français sur l’utilisation du fichier robots.txt.
Bonjour,
Je me suis mis sous WordPress, le truc que je viens de remarquer, c’est que pour acceder à mon site, l’adresse est ex : http://monsite.com/wordpress
J’aimerais qu’il soit : http://monsite.com
As-tu une idée sur la question ?
P.S : j’ai voulu tout mettre à la racine mais le problème c’est que tout mes billets et images pointent vers l’autre url !
Voici ce que j’ai trouvé sur le forum WordPress :
http://www.wordpress-fr.net/support/sujet-18186-resolu-migration-site-com-wordpress-site-com
Il arrive avec un fichier robots.txt…
Bonjour, Parfait ça devrait bloquer les robots spammeurs également en indiquant quel robots on veut voir passer sur notre site. Merci